You've Outgrown Your Charging Platform. Now What?

There's a moment every fast-growing charge point operator hits. You've built something real. Hundreds, maybe thousands, of charge points live across multiple markets. B2B partners are onboarded. Roaming agreements are running. Revenue is flowing. And then, quietly, the platform you built on starts to become the problem.
It doesn't break. It just can't keep up.
This is the inflection point we keep seeing across the industry. And the operators who navigate it well aren't the ones who find a better CPMS. They're the ones who realise the platform was never going to be the whole answer.
The Three Triggers
In almost every case, the pressure comes from one — or all three — of the following:
You've scaled past your first platform's ceiling. What worked at 500 charge points doesn't hold at 5,000. Reporting lags. Alerting misfires. Your ops team starts working around the system rather than through it. The platform isn't wrong — you've simply grown beyond what it was designed to handle at your pace.
You've acquired, or you're about to. M&A is accelerating across the EV charging space. Acquire one CPO and you inherit their CPMS, their tariff structures, their driver token registry, their roaming agreements. Suddenly you're running two or three systems for what should be one network. Every dashboard shows a different truth. Every report needs manual reconciliation.
Compliance keeps multiplying. ISO 15118 Plug&Charge. AFIR uptime reporting. Country-level VAT and invoicing rules that differ between Bulgaria, Romania, Germany and the Netherlands. These requirements don't arrive neatly — they accumulate, and each one adds a layer of coordination your team has to absorb.
The conventional response to all three is to migrate. Find a better platform, go through the painful process of moving OCPP connections, tariffs and driver tokens across, and hope the new system buys you another few years. But migration is not a strategy. It's a reset. And for operators on a genuine expansion spree, the reset never lasts long enough.
Why the Problem Isn't the Platform
Here's what the EV charging industry has been slow to acknowledge: the hard part of operating a large, multi-market charging network was never which CPMS you chose. It was the coordination layer around it.
When a charger goes offline at 2am on a motorway in Lithuania, someone needs to classify that fault, decide whether a remote reset will fix it, raise a field service ticket if it won't, notify the roaming partners if availability drops, and update the ERP. That workflow doesn't live inside a CPMS. It lives in the gap between your CPMS, your field service tool, your CRM, and your finance system — and in most networks today, it lives inside someone's head.
When you acquire a CPO, the technology is the easy part. The hard part is getting 500 B2B partner relationships, three years of tariff history, and an entirely different driver token registry into a state where your ops team can actually manage it — from day one, not month six.
When AFIR compliance comes up for renewal, someone needs to pull session data across every market, reconcile it against uptime thresholds, and produce a report that satisfies regulators in multiple jurisdictions simultaneously. That's not a CPMS feature. That's an operations problem.
The operators who scale smoothly are the ones who stop solving this with people and start solving it with a dedicated operations layer — one that sits above the CPMS, connects everything else, and automates the coordination work that currently falls through the gaps.
What a Platform-Agnostic Ops Nerve Centre Actually Does
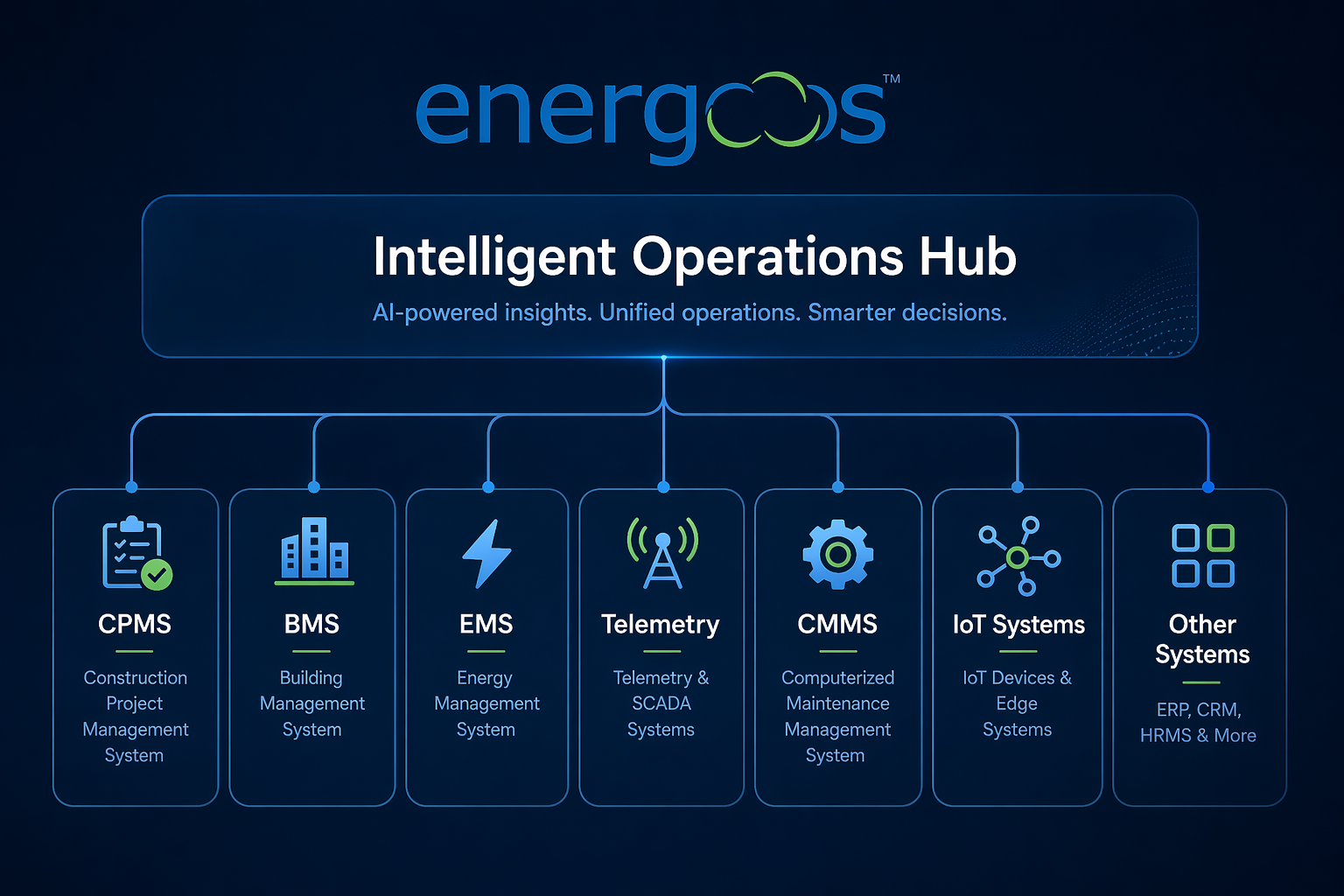
At Energos, we call this the nerve centre model. Not a replacement for your CPMS — a permanent layer above it, connecting your charging infrastructure to your business systems and automating the decisions that currently require human intervention.
Here's what that looks like in practice.
Fault-to-dispatch, without the manual chain. When an OCPP fault notification fires, the nerve centre classifies it automatically — hardware fault, connectivity issue, configuration error — and matches it against historical fault signatures to identify the most likely root cause. It attempts remote remediation first. If that fails, it raises a field service ticket with the parts list already attached, starts the SLA clock, and updates the ops dashboard. No phone calls. No email threads. No ops manager woken up at 2am to make a decision that a well-trained system should be making.
Zero-downtime migration, every time. When you need to move platforms — or absorb an acquired network onto your stack — the nerve centre manages the coordination. It shadow-syncs the new platform in parallel with the old one, validates that token registries match to zero tolerance, checks tariff parity, re-issues OCPI handshakes with roaming partners in the background, and executes the cutover in regional batches with automatic rollback if fault rates spike. Drivers never notice. Partners never notice. Your ops team executes a migration that used to take months in a matter of weeks.
M&A day one, not month six. Connect the acquired CPO's platform via OCPI or API bridge on closing day. The nerve centre normalises the asset registry — names, locations, connector types unified — surfaces tariff differences for review rather than merging them silently, and adds acquired driver tokens to the parent eMSP registry. Unified reporting is live from day one. You run one ops view, regardless of what's running underneath.
Compliance without the spreadsheets. A geofence rules engine applies the correct VAT schema and invoicing rules per site country, automatically. AFIR uptime reports are generated from session data without manual extraction. ISO 15118 Plug&Charge certificate lifecycles are managed and auto-renewed. When new regulatory requirements land, the affected sites are tagged, the relevant workflow is triggered, and your team is told what needs human sign-off — not left to discover the gap themselves.
Tariff operations at network scale. Stage a tariff change in the nerve centre. Run a simulation that shows projected revenue impact across every affected site. Approve it, and the new tariff pushes simultaneously to every CPMS platform in your stack via adapter. Settlement reports reconcile automatically against payment provider data. No manual syncing between systems. No version drift between markets.
Smart energy, automated. DSO signals and Agile tariff data feed directly into the nerve centre. Site-level demand forecasts combine with session occupancy models to produce a load schedule, which pushes automatically to chargers via OCPP smart charging profiles. The revenue impact of every load shift is logged per site. Grid participation becomes an ops function, not a specialist project.
The Outcomes That Matter
For operators at scale, the nerve centre model produces outcomes that platform switching alone never can.
Uptime that compounds. When faults are classified and actioned automatically, mean time to resolution drops — not just because response is faster, but because the system learns. Historical fault signatures improve with every incident. Remote remediation rates improve. FSE dispatches only happen when they're genuinely necessary.
Acquisitions that close cleanly. When the ops layer is platform-agnostic by design, absorbing an acquired network is a configuration task, not a transformation programme. The value from the acquisition starts accruing on day one, not after a six-month integration project.
Teams that do ops, not administration. The biggest hidden cost in a fast-growing charging network isn't energy or hardware — it's the operational overhead that accumulates as the network grows: manual fault tickets, tariff reconciliation spreadsheets, compliance exports, partner reporting, migration coordination. A nerve centre eliminates most of that overhead and redirects your team toward work that actually requires human judgement.
A stack that ages well. CPMS platforms will continue to evolve. Regulatory requirements will keep multiplying. The charging industry will consolidate further, meaning more M&A, more integration work, more multi-platform operations. An ops nerve centre that sits above all of that — platform-agnostic, API-first, built for coordination — doesn't become obsolete when your CPMS does. It gets more valuable as your network grows.
The Question Worth Asking
If your network is growing through acquisition, expansion across new markets, or both — the question isn't which CPMS to move to next.
It's whether your operations layer can keep up with the business you're building. The operators who reach 5,000, 10,000, 15,000 charge points without rebuilding their ops team from scratch every two years are the ones who answered that question early.
Energos.ai is a platform-agnostic O&M nerve centre for charge point operators. We sit above your CPMS stack, connecting your charging infrastructure to your business systems and automating the coordination work that scales poorly with people. If you're navigating an expansion or an acquisition, we'd like to talk.
Topics:
Operations & Maintenance
Energy & Utilities
Stop Losing Revenue to the "Out of Order" Sign.
Ready to guarantee 99.9% uptime? Join operations teams who’ve eliminated reactive maintenance and use the Energos Digital Operations Hub to automate their repairs and protect their bottom line. Get started for free today.
